Spring Batch desde Cero
Tabla de contenidos
Spring Batch es un framework de Java diseñado para aplicaciones que procesan grandes volúmenes de datos. En este artículo, exploraremos los conceptos básicos de esta tecnología, sus componentes principales y cómo puedes comenzar a utilizarla.
La aplicación que haremos procesará un archivo CSV que contiene datos de venta de una cafetería. Posteriormente, procesaremos los datos y, finalmente, generaremos un reporte en PDF.
Iniciar proyecto con Spring Initializr
Lo primero es dirigirnos a Spring Initializr, aquí podremos crear nuestro proyecto, las dependencias que necesitaremos son:
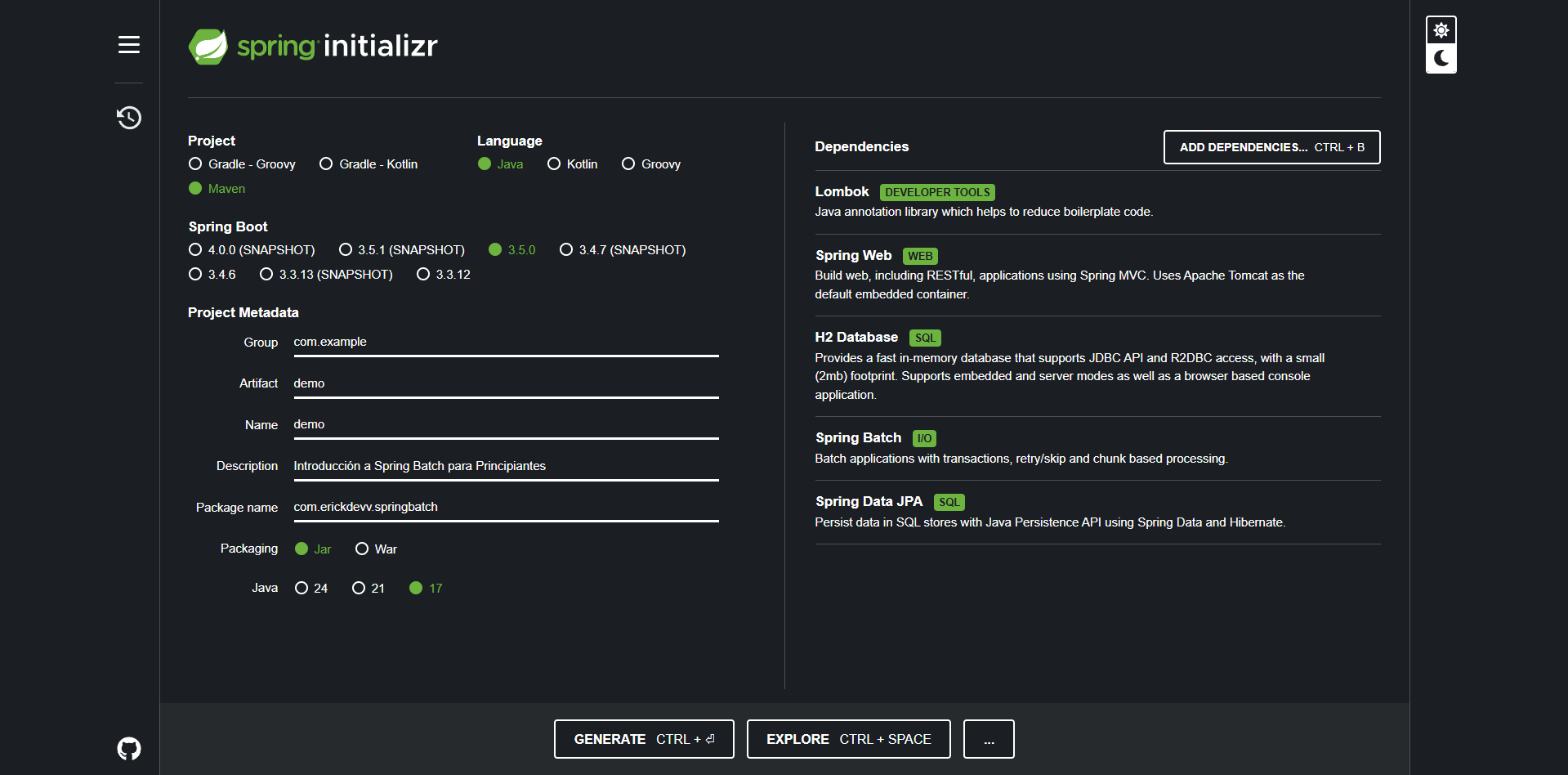
- Spring Batch: La dependencia principal para trabajar con Spring Batch.
- Spring Web: Para crear una API REST que nos permita arrancar el proceso de batch.
- Lombok: Para simplificar la creación de clases y reducir el boilerplate.
- Spring Data JPA: Para interactuar con la base de datos.
- H2 Database: Una base de datos en memoria que utilizaremos para almacenar los datos del procesamiento.
Una vez que hayas seleccionado las dependencias, haz clic en “Generate” para descargar el proyecto. Descomprime el archivo y ábrelo en tu IDE favorito.
Desarrollo del proyecto
Configuración base de datos y ruta de salida de PDF
Después, crearemos en el archivo application.properties la configuración de la base de datos H2:
server.port=2121
spring.batch.jdbc.initialize-schema=always
spring.datasource.initialize=true
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
spring.h2.console.enabled=true
spring.h2.console.path=/h2-console
spring.thymeleaf.cache=false
pdf.directory=<rutaSalidaPDF>
Recuerda cambiar <rutaSalidaPDF> por la ruta donde quieres que se guarden los archivos PDF generados.
Las demás propiedades configuran la base de datos H2 en memoria, lo cual es útil para pruebas y desarrollo. La consola H2 también está habilitada para que puedas ver los datos directamente desde el navegador, accediendo a http://localhost:2121/h2-console.
Puedes cambiar el puerto y las credenciales según tus necesidades.
Creación de archivo CSV de entrada y la plantilla del reporte PDF
Para este ejemplo, crearemos un archivo CSV de entrada que contendrá los datos de ventas de una cafetería. Crea un archivo llamado cafes.csv en la carpeta src/main/resources con el siguiente contenido:
id,name,type,price,size,quantity_sold,total_sales,commercial
1,Espresso,Café,2.50,Pequeño,120,300.00,Centro
2,Americano,Café,3.00,Mediano,150,450.00,Norte
3,Cappuccino,Café,3.50,Grande,100,350.00,Sur
4,Latte,Café,4.00,Grande,130,520.00,Centro
5,Mocha,Café,4.50,Grande,90,405.00,Norte
6,Macchiato,Café,3.75,Mediano,80,300.00,Sur
7,Flat White,Café,4.25,Mediano,110,467.50,Centro
8,Té Chai,Té,3.50,Grande,95,332.50,Norte
9,Té Verde,Té,3.00,Mediano,105,315.00,Sur
10,Chocolate Caliente,Bebida,3.75,Grande,85,318.75,Centro
11,Americano,Café,3.00,Mediano,300,900.00,Norte
Ahora crea un archivo de plantilla para el reporte en PDF. Crea un archivo llamado report_template.html en la carpeta src/main/resources/templates con el siguiente contenido:
<!DOCTYPE HTML>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<style>
body {
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
background-color: #f9f9f9;
margin: 40px;
}
h1 {
text-align: center;
color: #4a3f35;
font-size: 2em;
margin-bottom: 30px;
}
.coffe {
width: 100%;
border-collapse: collapse;
background-color: #fff;
box-shadow: 0 0 15px rgba(0, 0, 0, 0.1);
border-radius: 8px;
overflow: hidden;
}
.coffe th,
.coffe td {
padding: 16px 20px;
text-align: left;
}
.coffe th {
background-color: #6b4c3b;
color: #fff;
font-weight: bold;
text-transform: uppercase;
font-size: 0.9em;
letter-spacing: 0.05em;
}
.coffe tr:nth-child(even) {
background-color: #f2f2f2;
}
.coffe tr:hover {
background-color: #e9e0da;
}
</style>
</head>
<body>
<h1>Informe de Ventas</h1>
<table class="coffe">
<tr>
<th>Identificador</th>
<th>Nombre del producto</th>
<th>Tipo</th>
<th>Cantidad vendida</th>
<th>Total de ventas</th>
</tr>
<tr th:each="item, iterStat: ${quoteItems}">
<td th:text="${item.id}"></td>
<td th:text="${item.name}"></td>
<td th:text="${item.type}"></td>
<td th:text="${item.quantity_sold}"></td>
<td th:text="${item.total_sales}"></td>
</tr>
</table>
</body>
</html>
Ahora tenemos todo listo para comenzar a implementar la lógica de procesamiento de datos.
Creación de la entidad Cafe.java
Vamos a mapear los datos del archivo CSV a una entidad Java. Crea una clase llamada Cafe.java en la carpeta <tu_paquete>.entity con el siguiente contenido:
package com.example.ErickDevv.SpringBatch.entity;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Cafe {
private Long id;
private String name;
private String type;
private Double price;
private String size;
private Integer quantity_sold;
private Double total_sales;
private String commercial;
}
Como podemos observar, Lombok nos aporta una forma sencilla de crear getters, setters, constructores y el método toString sin necesidad de escribir mucho código.
Creación de la interfaz PdfGenerateService.java
Crea una interfaz llamada PdfGenerateService.java en el paquete <tu_paquete>.service con el siguiente contenido:
package com.example.ErickDevv.SpringBatch.service;
import java.util.Map;
interface PdfGenerateService {
void generatePdfFile(String templateName, Map<String, Object> data, String pdfFileName);
}
Actualización de las dependencias en el archivo pom.xml
Asegúrate de que tu archivo pom.xml tenga las siguientes dependencias para trabajar con PDF y Thymeleaf:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>org.xhtmlrenderer</groupId>
<artifactId>flying-saucer-pdf</artifactId>
<version>9.11.4</version>
</dependency>
Thymeleaf se encargará de procesar las plantillas HTML y Flying Saucer se encargará de convertir el HTML a PDF.
Creación del servicio de generación de PDF
Para generar el PDF, crearemos un servicio que se encargue de la lógica de generación del archivo. Crea una clase llamada PdfGenerateServiceImpl .java en el paquete <tu_paquete>.service con el siguiente contenido (implementando la interfaz previamente creada):
package com.example.ErickDevv.SpringBatch.service;
import com.lowagie.text.DocumentException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import org.thymeleaf.TemplateEngine;
import org.thymeleaf.context.Context;
import org.xhtmlrenderer.pdf.ITextRenderer;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.util.Map;
@Service
public class PdfGenerateServiceImpl implements PdfGenerateService {
private Logger logger = LoggerFactory.getLogger(PdfGenerateServiceImpl.class);
@Autowired
private TemplateEngine templateEngine;
@Value("${pdf.directory}")
private String pdfDirectory;
@Override
public void generatePdfFile(String templateName, Map<String, Object> data, String pdfFileName) {
Context context = new Context();
context.setVariables(data);
String htmlContent = templateEngine.process(templateName, context);
try {
FileOutputStream fileOutputStream = new FileOutputStream(pdfFileName);
ITextRenderer renderer = new ITextRenderer();
renderer.setDocumentFromString(htmlContent);
renderer.layout();
renderer.createPDF(fileOutputStream, false);
renderer.finishPDF();
} catch (FileNotFoundException e) {
logger.error(e.getMessage(), e);
} catch (DocumentException e) {
logger.error(e.getMessage(), e);
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
}
Creación del Writer
Para no hacer muy largo este artículo, únicamente vamos a separar la lógica de escritura de datos en una clase llamada CafeItemWriter.java. Crea esta clase en el paquete <tu_paquete>.batch.writer con el siguiente contenido:
package com.example.ErickDevv.SpringBatch.batch.writer;
import org.springframework.batch.item.Chunk;
import org.springframework.batch.item.support.AbstractItemStreamItemWriter;
import org.springframework.stereotype.Component;
import com.example.ErickDevv.SpringBatch.entity.Cafe;
import com.example.ErickDevv.SpringBatch.service.PdfGenerateServiceImpl;
import java.util.*;
import java.util.stream.Collectors;
@Component
public class CafeItemWriter extends AbstractItemStreamItemWriter<Cafe> {
private final PdfGenerateServiceImpl pdfGenerateService;
public CafeItemWriter(PdfGenerateServiceImpl pdfGenerateService) {
this.pdfGenerateService = pdfGenerateService;
}
@Override
public void write(Chunk<? extends Cafe> chunk) throws Exception {
Map<String, Cafe> cafeReportMap = new HashMap<>();
Thread.sleep(30000);
for (Cafe cafe : chunk.getItems()) {
cafeReportMap.merge(cafe.getName(), cloneCafe(cafe), (existing, incoming) -> {
existing.setQuantity_sold(existing.getQuantity_sold() + incoming.getQuantity_sold());
existing.setTotal_sales(existing.getTotal_sales() + incoming.getTotal_sales());
return existing;
});
}
List<Cafe> sortedCafeList = cafeReportMap.values().stream()
.sorted(Comparator.comparingDouble(Cafe::getTotal_sales).reversed())
.collect(Collectors.toList());
for (int i = 0; i < sortedCafeList.size(); i++) {
sortedCafeList.get(i).setId((long) (i + 1));
}
Map<String, Object> data = new HashMap<>();
data.put("quoteItems", sortedCafeList);
pdfGenerateService.generatePdfFile("report_template", data, "coffee_report.pdf");
}
private Cafe cloneCafe(Cafe source) {
Cafe clone = new Cafe();
clone.setId(source.getId());
clone.setName(source.getName());
clone.setSize(source.getSize());
clone.setType(source.getType());
clone.setPrice(source.getPrice());
clone.setQuantity_sold(source.getQuantity_sold());
clone.setTotal_sales(source.getTotal_sales());
return clone;
}
}
Creación de la configuración general del Batch
Ahora crearemos la configuración del batch. Crea una clase llamada BatchConfig.java en el paquete <tu_paquete>.config con el siguiente contenido:
package com.example.ErickDevv.SpringBatch.config;
import java.math.BigDecimal;
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.repository.support.JobRepositoryFactoryBean;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.LineMapper;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
import com.example.ErickDevv.SpringBatch.batch.writer.CafeItemWriter;
import com.example.ErickDevv.SpringBatch.entity.Cafe;
import lombok.RequiredArgsConstructor;
@Configuration
@RequiredArgsConstructor
public class BatchConfig {
private final DataSource dataSource;
private static final String[] FIELDS = new String[] { "id", "name", "type", "price", "size", "quantity_sold", "total_sales", "commercial" };
private static final String CSV_FILE = "C:\\Users\\erick\\Desktop\\YouTube - ErickDevv\\ErickDevv.SpringBatch\\ErickDevv.SpringBatch\\src\\main\\resources\\cafes.csv";
@Autowired
private CafeItemWriter cafeItemWriter;
@Bean
public JobRepository myJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(platformTransactionManager());
factory.afterPropertiesSet();
return factory.getObject();
}
@Bean
public PlatformTransactionManager platformTransactionManager() {
return new DataSourceTransactionManager(dataSource);
}
@Bean
public LineMapper<Cafe> lineMapper() {
DefaultLineMapper<Cafe> lineMapper = new DefaultLineMapper<>();
DelimitedLineTokenizer lineTokenizer = new DelimitedLineTokenizer();
lineTokenizer.setDelimiter(",");
lineTokenizer.setStrict(true);
lineTokenizer.setNames(FIELDS);
BeanWrapperFieldSetMapper<Cafe> fieldSetMapper = new BeanWrapperFieldSetMapper<>();
fieldSetMapper.setTargetType(Cafe.class);
lineMapper.setLineTokenizer(lineTokenizer);
lineMapper.setFieldSetMapper(fieldSetMapper);
return lineMapper;
}
@Bean
public ItemProcessor<Cafe, Cafe> processor() {
return cafe -> {
cafe.setPrice(BigDecimal.valueOf(cafe.getPrice()).multiply(BigDecimal.valueOf(1.1)).doubleValue());
return cafe;
};
}
@Bean
public FlatFileItemReader<Cafe> readerCSV() {
FlatFileItemReader<Cafe> itemReader = new FlatFileItemReader<>();
itemReader.setResource(new FileSystemResource(CSV_FILE));
itemReader.setEncoding("UTF-8");
itemReader.setName("csvReader");
itemReader.setLinesToSkip(1);
itemReader.setStrict(true);
itemReader.setLineMapper(lineMapper());
return itemReader;
}
@Bean
public Step step1(JobRepository jobRepository) throws Exception {
return new StepBuilder("FirstStepCSV", jobRepository)
.<Cafe, Cafe>chunk(100, platformTransactionManager())
.reader(readerCSV())
.processor(processor())
.writer(cafeItemWriter)
.build();
}
@Bean
public Job myjob(JobRepository jobRepository) throws Exception {
return new JobBuilder("FirstJob", jobRepository)
.start(step1(jobRepository))
.build();
}
}
Como puedes ver hemos creado un Job y un Step que se encargan de leer el archivo CSV, procesar los datos y escribir el resultado en un archivo PDF. El ItemProcessor se encarga de aplicar una lógica de negocio simple, como aumentar el precio de cada café en un 10%.
Creación de la configuración de Thymleaf
Para que Thymeleaf pueda procesar las plantillas HTML, necesitamos configurarlo. Crea una clase llamada ThymeleafConfig.java en el paquete <tu_paquete>.config con el siguiente contenido:
package com.example.ErickDevv.SpringBatch.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.thymeleaf.templateresolver.ClassLoaderTemplateResolver;
@Configuration
public class ThymeleafConfig {
@Bean
public ClassLoaderTemplateResolver emailTemplateResolver() {
ClassLoaderTemplateResolver pdfTemplateResolver = new ClassLoaderTemplateResolver();
pdfTemplateResolver.setPrefix("templates/");
pdfTemplateResolver.setSuffix(".html");
pdfTemplateResolver.setTemplateMode("HTML5");
pdfTemplateResolver.setCharacterEncoding("UTF-8");
pdfTemplateResolver.setOrder(1);
return pdfTemplateResolver;
}
}
Creación del controlador para iniciar el Job
Crea un controlador que permita iniciar el Job de procesamiento de datos. Crea una clase llamada BatchController.java en el paquete <tu_paquete>.controller con el siguiente contenido:
package com.example.ErickDevv.SpringBatch.controller;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/batch")
public class BatchController {
@Autowired
private JobLauncher jobLauncher;
@Autowired
private Job myJob;
@GetMapping("/start")
public ResponseEntity<String> startBatchJob() {
try {
JobParameters jobParameters = new JobParametersBuilder()
.addLong("startTime", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(myJob, jobParameters);
return ResponseEntity.ok("Batch job started successfully.");
} catch (Exception e) {
return ResponseEntity.status(500).body("Failed to start batch job: " + e.getMessage());
}
}
}
Este controlador expone un endpoint /batch/start que, al ser llamado, inicia el Job de procesamiento de datos.
Prueba del proyecto
Para probar el proyecto, asegúrate de que tu base de datos H2 esté configurada correctamente y que el archivo CSV esté en la ruta especificada. Luego, ejecuta la aplicación y accede a http://localhost:2121/h2-console para verificar que la base de datos se haya inicializado correctamente.
Para iniciar el Job, puedes hacer una petición GET a http://localhost:2121/batch/start. Esto iniciará el procesamiento de datos y generará un archivo PDF con el reporte de ventas en la ruta especificada en application.properties.
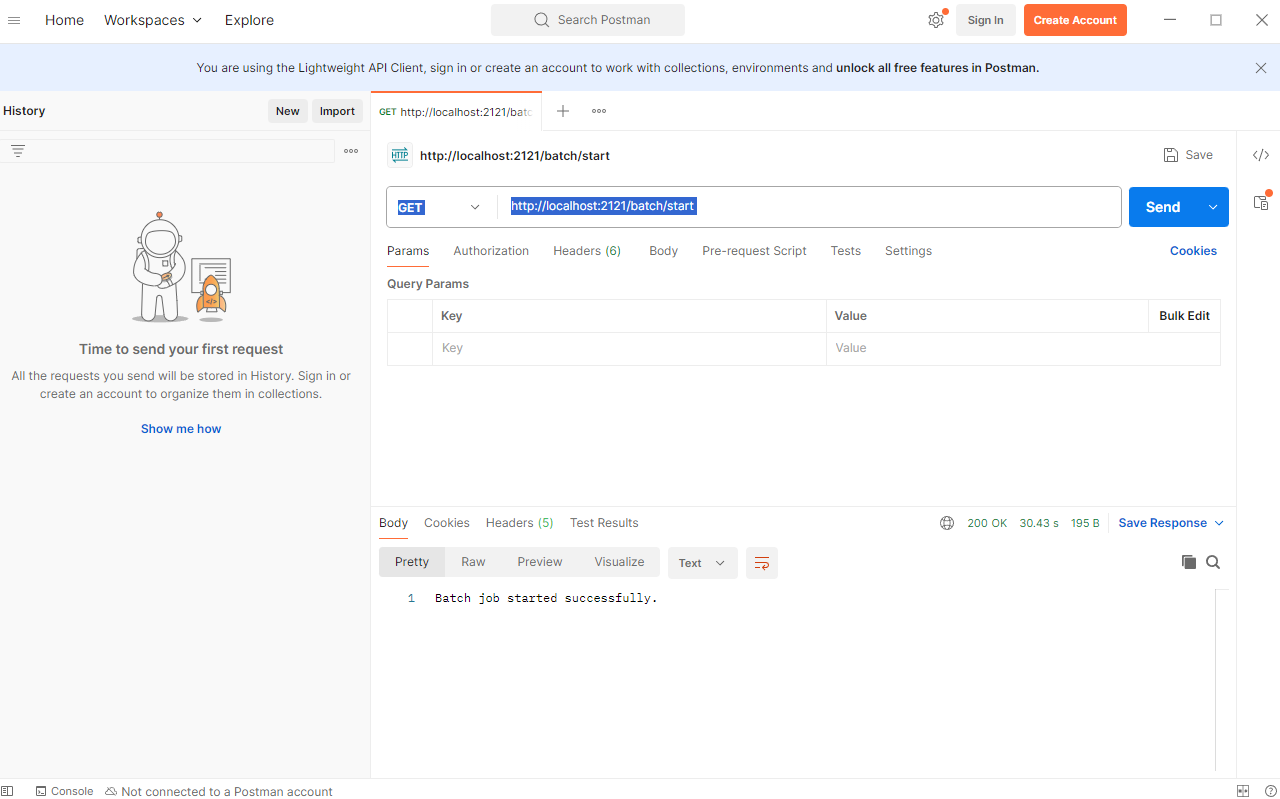
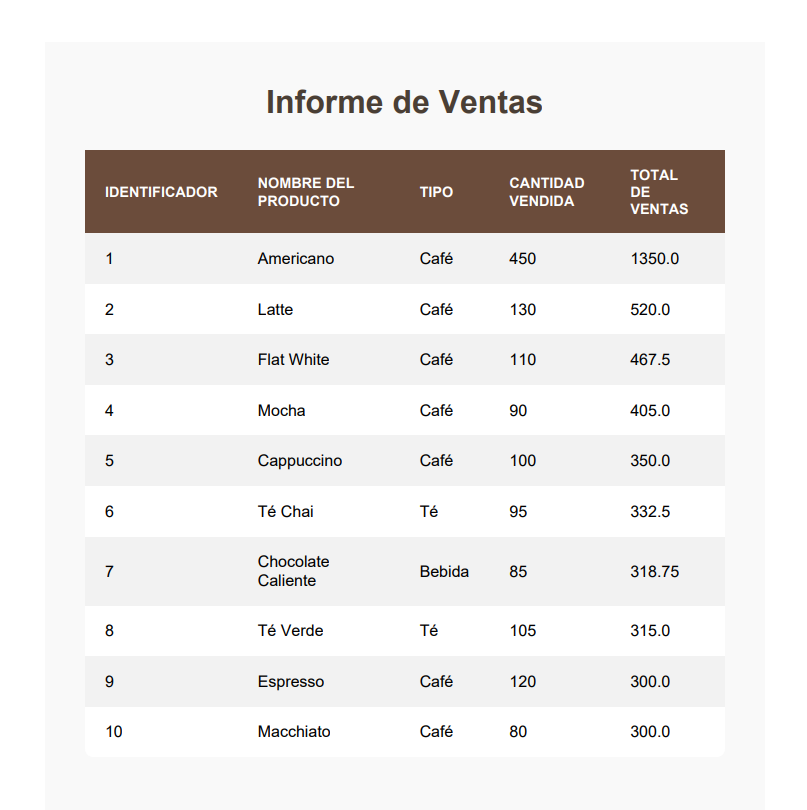
Ahora veamos el contenido del archivo PDF generado:
Monitorización del Job
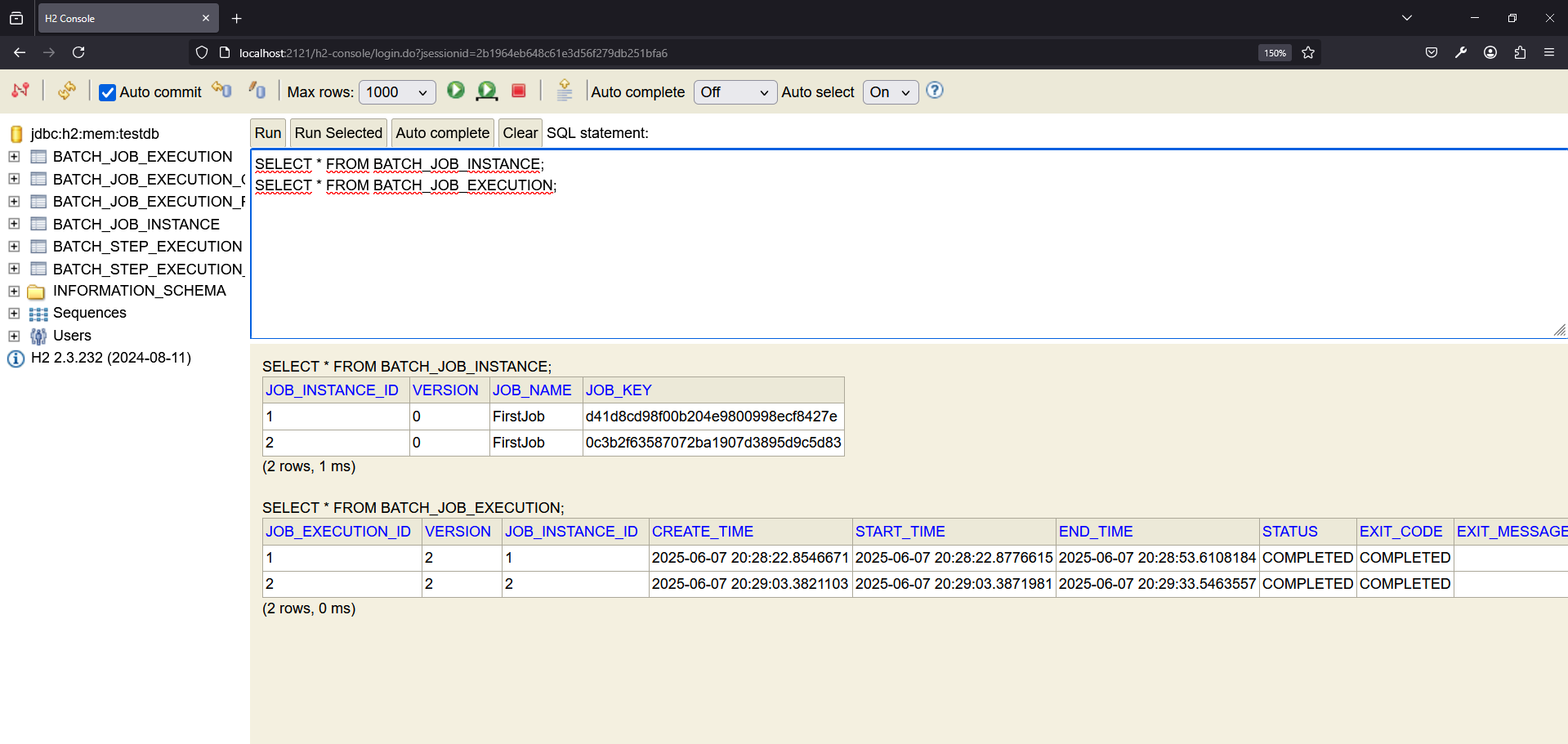
Para monitorizar el estado de los Jobs y Steps, puedes utilizar la consola H2. Accede a http://localhost:2121/h2-console e ingresa las credenciales configuradas en application.properties. Luego, ejecuta las siguientes consultas SQL para ver el estado de los Jobs:
SELECT * FROM BATCH_JOB_INSTANCE;
SELECT * FROM BATCH_JOB_EXECUTION;
Esto te permitirá ver los Jobs que se han ejecutado, su estado y otros detalles relevantes.
Conclusión
Spring Batch es una herramienta muy potente a la hora de procesar datos, como hemos visto, tenemos una estructura bien definida que si bien nuestro ejemplo fue relativamente sencillo el framework da todas las herramientas para poder escalar, lo que a mi parecer produce seguridad para su uso en proyectos futuros.
¿Te gusta mi contenido? ¡Invítame un café! ☕
Buy Me a Coffee